Ricky 发现本周某天凌晨开始公司大量的 KVM 虚拟机和部分物理服务器突然成批地挂掉(共百余台),刚开始并不知道是什么原因造成的,在 Convirture 管理平台 reboot 一下虚拟机和强制重启一下物理服务器就暂时没问题了,但过了几个小时又有 KVM 虚拟机开始挂掉(物理服务器应该是没有挂第二次的)。
KVM 虚拟机和部分物理服务器都没有办法 SSH 登录上去了,VNC 上去发现大部分 KVM 虚拟机报以下几种错误:
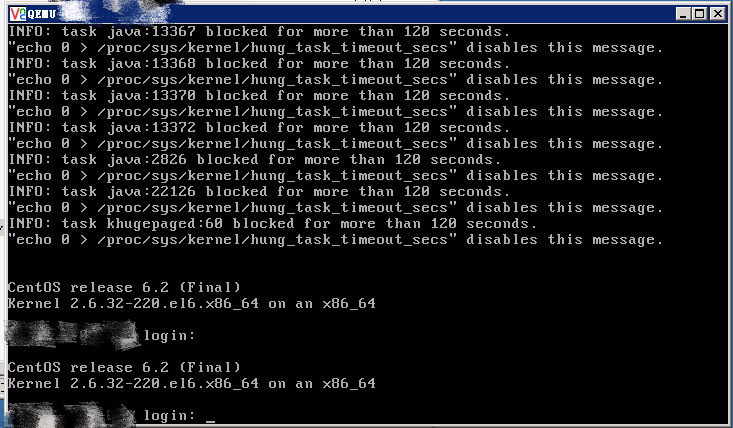
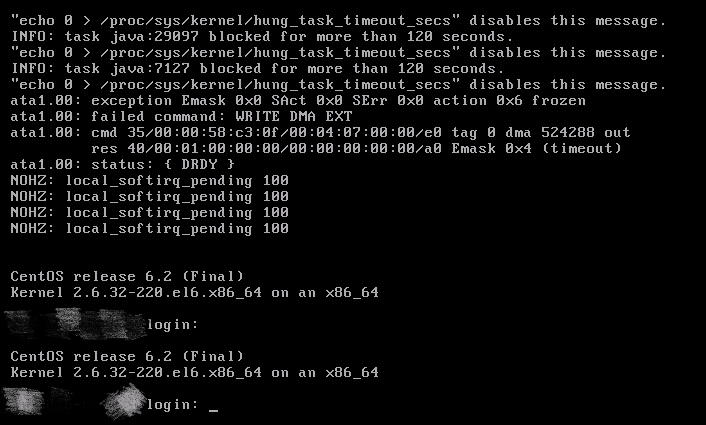

最后经 Ricky 的综合分析发现,是公司内部开发的一套系统造成的。【泪奔中 o(╥﹏╥)o 】
在开发同事那边有一套专门用于监控服务器 CPU 占用率、TCP 连接数、内存使用情况和代码发布、备份、回滚等等的系统,每台服务器(包括 KVM 虚拟机和物理服务器)上都安装有一个客户端用于连接这套系统的 ActiveMQ 消息队列服务器。
在发生此次大规模宕机之前就已经出现部分服务器的客户端突然无法连接上这套系统的情况了,但是经过重启和重装客户端后又可以再次连上了。
当公司的服务器(包括 KVM 虚拟机和物理服务器)增加到一定数量的时候(目前 KVM 虚拟机和物理服务器共计 1600 余台),ActiveMQ 消息队列服务器开始撑不住了。因为每台服务器上的客户端都会发起 TCP 连接去连接 ActiveMQ 消息队列服务器。
再加上大规模宕机后发现这套系统的客户端有一个 bug ,就是在客户端发现连接不上 ActiveMQ 消息队列服务器后还会发起新的 TCP 连接去连接 ActiveMQ 消息队列服务器,可能还会随之创建新的 Java 线程,而之前发起的 TCP 连接并没有关闭,从报错信息来看 Java 线程也是没有结束的。
所以服务器这头会有几十到几百个不等的 TCP 连接拥塞在 SYN_SENT 状态(即 TCP 三次握手并没有完成,此时客户端正在等待 ActiveMQ 消息队列服务器的响应);而此时的 ActiveMQ 消息队列服务器的网络或者网卡因为大量的 TCP 连接涌入早已处在崩溃的状态(即 ActiveMQ 消息队列服务器早已无法建立那么多的 TCP 连接了)。
ActiveMQ 消息队列服务器崩溃完全可以理解,但是为什么会有服务器发生宕机呢?在这 1600 余台服务器中的百余台服务器是自己把自己拖垮的。因为服务器这边会有大量的 TCP 连接拥塞在 SYN_SENT 状态,Java 代码创建的一些线程可能也会随之拥塞( task java xxxxx blocked for more than 120 seconds ),那么 CPU 就要反复地去检查这些 TCP 连接和 Java 线程( CPU 会去看 ActiveMQ 消息队列服务器响应了哪个 TCP 连接、哪个 Java 线程能够随之执行下去),同时内存也会被大量占用( Out of memory : Kill process xxxxx ( java ) score xxx or sacrifice child ),所以最终就发生了如上事故。
那为什么 KVM 虚拟机挂的比较多而物理服务器却没有挂那么多呢?因为从抗压能力和综合性能来看,很明显物理服务器要比虚拟机好很多。
最后,还是比较享受这种在掌控与失控边缘徘徊的感觉。
发表评论?