最近 Ricky 这里有一个批量检测 URL 是否可以访问的需求,于是写了一个 Python 脚本来实现这个需求,在此 Ricky 把代码分享出来。
这个脚本会对每个 URL 检测四次,其中 http 检测两次,https 检测两次;之所以是各两次是因为会使用两个包来检测( urllib 和 urllib2 )。即:
- urllib 检测 http ;
- urllib 检测 https ;
- urllib2 检测 http ;
- urllib2 检测 https 。
共四次。
首先是包的导入和浏览器所使用的 User-Agent 的定义:
# coding=utf-8
import httplib, urllib, urllib2, ssl, time, os
HEADERS = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36'}
紧接着是 show_status_urllib(url) 和 show_status_urllib2(url) 两个检测方法,这里面捕获了大量的异常;以及一个用于处理所返回的网页状态码的函数 return_code(function_name, response) :
def show_status_urllib(url):
function_name = 'urllib'
try:
response = urllib.urlopen(url)
except IOError, e:
return False, function_name + ' : IOError - ' + e.message
except ssl.CertificateError, e:
return False, function_name + ' : CertificateError - ' + e.message
except httplib.BadStatusLine, e:
return False, function_name + ' : httplib.BadStatisLine - ' + e.message
else:
return return_code(function_name, response)
def show_status_urllib2(url):
function_name = 'urllib2'
try:
# request = urllib2.Request(url)
request = urllib2.Request(url, '', HEADERS)
response = urllib2.urlopen(request)
except urllib2.HTTPError, e:
return False, function_name + ' : HTTPError code ' + str(e.code)
except urllib2.URLError, e:
return False, function_name + ' : URLError - ' + str(e.reason)
except IOError, e:
return False, function_name + ' : IOError - ' + e.message
except ssl.CertificateError, e:
return False, function_name + ' : CertificateError - ' + e.message
except httplib.BadStatusLine, e:
return False, function_name + ' : httplib.BadStatisLine - ' + e.message
else:
return return_code(function_name, response)
def return_code(function_name, response):
code = response.getcode()
if code == 404:
return False, function_name + ' : code 404 - Page Not Found !'
elif code == 403:
return False, function_name + ' : code 403 - Forbidden !'
else:
return True, function_name + ' : code ' + str(code) + ' - OK !'
接下来是一个用于处理日志的函数,以及一个对 URL 进行四次检测的函数:
def return_log(protocol, is_true, url, urllib_log, urllib2_log):
if is_true:
return '### ' + protocol + '_YES ### ' + url + ' → (' + urllib_log + ' )( ' + urllib2_log + ')'
else:
return '### ' + protocol + '_NO ### ' + url + ' → (' + urllib_log + ' )( ' + urllib2_log + ')'
def request_url(url):
url = url.strip().replace(" ", "").replace("\n", "").replace("\r\n", "")
http_url = 'http://' + url
is_http_urllib_true, http_urllib_log = show_status_urllib(http_url)
is_http_urllib2_true, http_urllib2_log = show_status_urllib2(http_url)
https_url = 'https://' + url
is_https_urllib_true, https_urllib_log = show_status_urllib(https_url)
is_https_urllib2_true, https_urllib2_log = show_status_urllib2(https_url)
line = return_log('HTTP', is_http_urllib_true and is_http_urllib2_true, http_url, http_urllib_log, http_urllib2_log) + return_log('HTTPS', is_https_urllib_true and is_https_urllib2_true, https_url, https_urllib_log, https_urllib2_log)
print line
return line
接下来是一个对日志进行分类并将日志保存到文本文件的函数:
def save_log(log_file, log_http_no_and_https_no_file, log_http_no_but_https_yes_file, log_http_yes_but_https_no_file, line):
line += '\n'
log_file.write(line)
log_file.flush()
if '### HTTP_NO ###' in line:
if '### HTTPS_NO ###' in line:
log_http_no_and_https_no_file.write(line)
log_http_no_and_https_no_file.flush()
elif '### HTTPS_YES ###' in line:
log_http_no_but_https_yes_file.write(line)
log_http_no_but_https_yes_file.flush()
elif '### HTTP_YES ###' in line and '### HTTPS_NO ###' in line:
log_http_yes_but_https_no_file.write(line)
log_http_yes_but_https_no_file.flush()
最后是主函数,主函数这里也提供了两种检测方法:一种是通过列表来读取出需要检测的 URL ,另一种是通过文本文件( url.txt )来读取出需要检测的 URL :
def main():
if not os.path.exists('logs'):
os.mkdir('logs')
now_time = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
log_file = open('logs/log-' + now_time + '.txt', 'a')
log_http_no_and_https_no_file = open('logs/log-' + now_time + '-http-no-and-https-no.txt', 'a')
log_http_no_but_https_yes_file = open('logs/log-' + now_time + '-http-no-but-https-yes.txt', 'a')
log_http_yes_but_https_no_file = open('logs/log-' + now_time + '-http-yes-but-https-no.txt', 'a')
print 'URL Testing For List :\n'
url_of_list = ['www.baidu.com', 'news.baidu.com/guonei', 'www.qq.com', 'www.taobao.com']
for url in url_of_list:
save_log(log_file, log_http_no_and_https_no_file, log_http_no_but_https_yes_file, log_http_yes_but_https_no_file, request_url(url))
print '\nURL Testing For TXT File :\n'
url_file = open("url.txt")
for url in url_file.xreadlines():
save_log(log_file, log_http_no_and_https_no_file, log_http_no_but_https_yes_file, log_http_yes_but_https_no_file, request_url(url))
url_file.close()
log_file.close()
log_http_no_and_https_no_file.close()
log_http_no_but_https_yes_file.close()
log_http_yes_but_https_no_file.close()
if __name__ == "__main__":
main()
Ricky 是使用 PyCharm 来编写 Python 代码的,目录结构如下图所示:
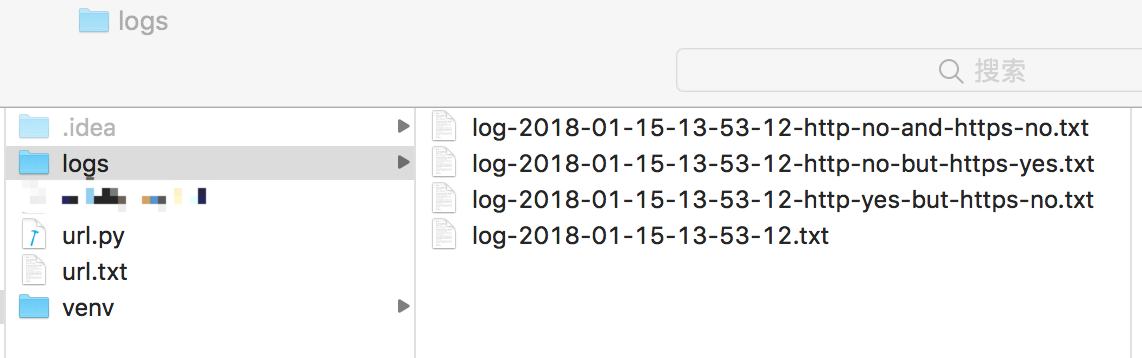
其中 logs 文件夹及其目录下的 .txt 文本文件均会在 main() 函数中自动创建。
示例
url.txt 文件里有如下内容:
www.baidu.com news.baidu.com/guonei www.qq.com www.taobao.com

源代码下载
请参见文章下方的 Article Attachments 部分,或者点击右侧链接:url.py 和 url.txt(Python 2.7.14 ,亲测可执行)
Next
2.0 的版本已发布(详情请点击这里),2.0 的版本使用多线程的方式并行检测 URL ,减少检测所需要的时间;以及对日志的写入进行了优化。
其他相关文章:
本文参考自:
- Python 获取网页状态码:http://blog.csdn.net/edward2jason/article/details/38379931
发表评论?